JavaScript Regular Expressions
-
بنحكي في هذا الدرس عن regular expression الي هو عبارة عن سلسلة من الأحرف التي تشكل نمط بحث(search pattern) داخل النصوص بحيث يمكن التحكم بعملية البحث، وتحديد طريقة البحث داخل النصوص، كما تستخدم أيضا في عمليات استبدال النصوص text replace operations. يدعم JavaScript مجموعه من أنماط البحث (search pattern) ويمكن استخدام حرف واحد single character او اكثر من ذلك (نمط معقد complicated pattern)
انشاء regular expression
طريقة الكتابة
const re = /ab+c/;
تكتب بإضافة النمط pattern بين علامتي الشرطة المائلة slashes
مثال:
Const re =/Devkum/g
شو يعني هذا التركيب.
التركيب كامل يعرف باسم regular expressions
الكلمة Devkum هي النص المطلوب استخدامه للبحث وهو النمط (pattern )
الحرف الأخير g هو نمط وطريقة البحث (g تعني ان يكون البحث case-sensitive)
regular expressions عبارة عن objects يستخدم غالبا مع النصوص string methods التالية : ()search() ، replace()، match
استخدام ()String search
حكينا عن البحث باستخدام search في JavaScript وحكينا ان من خلال طريقة ()search يتم البحث في السلاسل عن قيمة محددة وتعيد موضع المطابقة للنص المراد البحث عنه.
للمزيد حول ذلك انقر هنا .
تمام كيف ممكن نستخدم regular expressions مع هذه الطريقة
نطبق المثال التالي :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript Templates Literals</h3>
<p id="Date"></p>
<script>
let text = "Welcome to Devkum, A community of thousands of aspiring people!";
let n = text.search("Devkum");
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
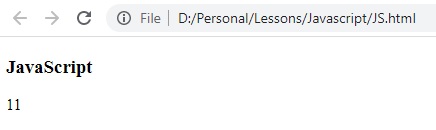
لاحظ ان مكان اول حرف من كلمة Devkum يقع في الموضع رقم 11 (البداية تكون من صفر) بناء عليه تم طباعه الرقم 11
لحد الان طبقنا طريقة البحث الاعتيادية وما طبقنا regular expressions
نغير الان كملة Devkum الى devkum وبكون الكود بالشكل التالي :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript Templates Literals</h3>
<p id="Date"></p>
<script>
let text = "Welcome to Devkum, A community of thousands of aspiring people!";
let n = text.search("devkum");
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة
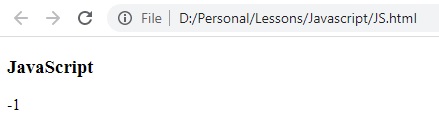
النتيجة -1 لان اول حرف من كلمة devkum حرف صغير ولا يوجد كلمة بهذه المواصفات في النص السابق.
تمام هون دور regular expressions في البحث.
كيف ممكن نبحث عن الكلمة السابقة بغض النظر عن حال الاحرف.
الجواب : باستخدام regular expressions
نطبق الكود التالي ونشوف النتيجة:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Welcome to Devkum, A community of thousands of aspiring people!";
let n = text.search(/devkum/i);
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة
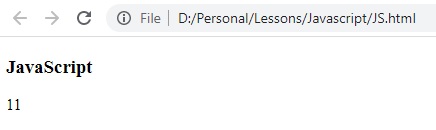
لاحظ ان تم ارجاع الرقم 11 وهو اول موضع لبداية الكلمة devkum، ايضا ما تم التحقق من حالة الاحرف. السبب استخدام regular expressions المسمى i والي من خلالو بتم البحث بغض النظر عن حالة الاحرف(case-insensitive)
تمام لو المطلوب نستخدم regular expressions مع التحقق من حالة الاحرف(case-sensitive) بنستخدم الامر g
بكون شكل الكود :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Welcome to Devkum, A community of thousands of aspiring people!";
let n = text.search(/devkum/g);
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة
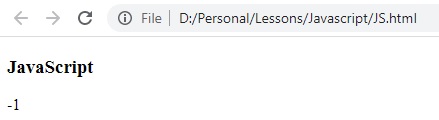
لان النص السابق لا يحتوي على كلمة devkum فا تم ارجاع الرقم -1
استخدام ()String replace
حكينا ان الامر replace يستخدم لاستبدال نص بنص اخر في السلاسل.
تنذكر هذا الحكي بمثال
طبق المثال التالي :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Welcome to WebSite, A community of thousands of aspiring people!";
let n = text.replace("WebSite","Devkum");
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة :
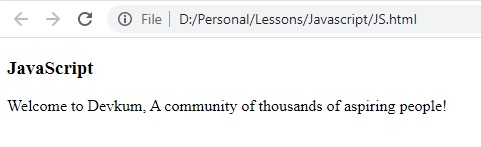
لاحظ ان النص الأصل يحتوي على كلمة WebSite وقمنا باستبدال هذا النص بكلمة Devkum
استخدام regular expressions مع replace
الاستخدام تماما نفس الطريقة السابقة في search.
استخدام regular expressions المسمى i
طبق الكود التالي :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Welcome to WebSite, A community of thousands of aspiring people!";
let n = text.replace(/webSite/i,"Devkum");
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة :
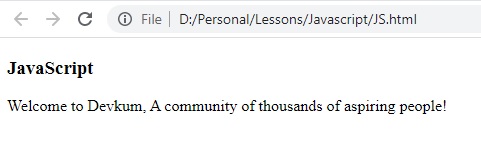
تم استبدال النص المطلوب رغم ان الكلمة webSite غير مطابقة اول حرف w حرف صغير ، والسبب استخدام الامر i الى بتعامل مع (case-insensitive)
ونفس الفكرة مع الامر g
اذا كنت تريد تطبيق بحث افضل واقوى يفضل استخدام الامر i حتى لا تكون حال الاحرف مهمه (يتم البحث بغض النظر عن حالة الاحرف).
الجدول التالي يوضح العلامات التي يمكن استخدامها في Regular expressions، ويمكن استخدام العلامات بشكل منفصل أو معًا بأي ترتيب
| العلامة flag | الوصف Description |
| d | إنشاء مؤشرات لمطابقات السلاسل الفرعية. |
| g | بحث global مع Case-sensitive، يتم البحث عن جميع الكلمات المتطابقه |
| i | بحث Case-insensitive |
| m | بحث متعدد الاسطر Multi-line search. |
| s | يسمح باستخدام . لتتناسب مع أحرف السطر الجديد. match newline characters |
| u | "unicode" تعامل مع pattern على أنه سلسلة من unicode code points. |
| y | يستخدم لإجراء بحث ثابت (sticky) بحيث يطابق من بداية الموضع الحالي في السلسلة |
الأنماط Patterns في Regular Expression
يمكن استخدام الاقواس [] او () لتحديد نمط البحث.
استخدام الاقواس [ ]
نطبق مثال حتى نفهم الموضوع:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Welcome to WebSite, A community of thousands of aspiring people!";
let n = text.match(/[t]/g);
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة :
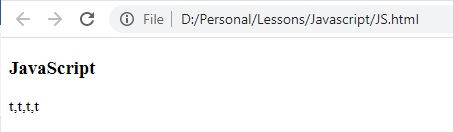
تم البحث عن الحرف t باستخدام الامر g يعني برجع جميع التطابقات الموجودة، وفعليا في هذا المثال لا فائدة من استخدام الاقواس [ ] لان المطلوب البحث عنه حرف واحد. (جرب تحذف الاقواس وشوف النتيجة، اكيد نفسها).
طيب شو الفائدة من الاقواس
الفائدة من الاقواس هي تحديد نطاق للبحث. يعني لو كان المطلوب البحث عن الاحرف بين t و x يعني نطاق البحث بكون للأحرف (t,u,v,w,x) بنستخدم الاقواس
نعدل على المثال السابق حتى نفهم الموضوع:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Welcome to WebSite, A community of thousands of aspiring people!";
let n = text.match(/[t-x]/g);
document.write( n);
document.write("<br>");
</script>
</body>
</html>
النتيجة :
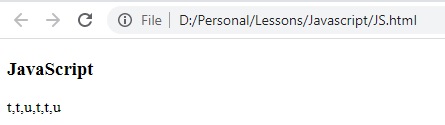
تم ارجاع جميع الاحرف الموجود بين t و x
ممكن نفس الطريقة السابقة تستخدم مع الأرقام
مثال
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
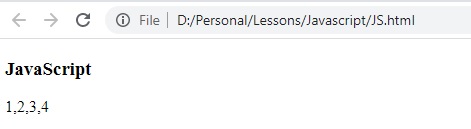
let text = "123456789";
let result = text.match(/[1-4]/g);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة
الاحرف الخاصة Metacharacters
هي عبارة عن احرف محدده تستخدم لأغراض معينه
الحرف d\
يستخدم لإيجاد الأرقام في النص
مثال :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Current Temperature is 35 C";
let result = text.match(/\d/g);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
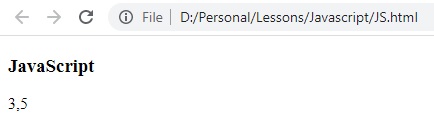
تم ارجاع جميع الأرقام الموجدة في النص
الحرف s\
يستخدم لإيجاد المسافات الفارغة في النص
مثال :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Current Temperature is 35 C";
let result = text.match(/\s/g);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة :
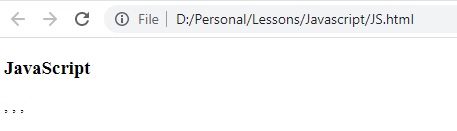
الحرف b\
يستخدم للبحث عن التطابق في بداية الكلمة ( في حال عدم وجود تطابق في بداية الكلمات لن يتم إيجاد شيء) باستخدام الامر bword\. واذا كان المطلوب البحث في اخر الكملة يستخدم الامر word\b
مثال:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "HELLO, LOOK AT YOU!";
let result = text.search(/\bLO/);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة :
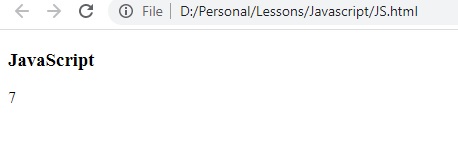
لان الحرفين LO موجودات في اول الكملة LOOK تم ارجاع المكان رقم 7 (لاحظ ان الحرفين موجودين كمان في الكلمة HELLO لكن ليس في اول الكلمة)
استخدام b\ في اخر الكلمة
عدل على الكود السابق الى :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "HELLO, LOOK AT YOU!";
let result = text.search(/LO\b/);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة :
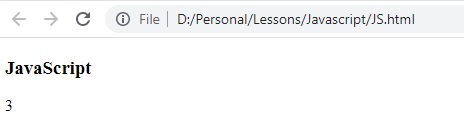
الكود السابق يعمل في بداية ونهاية الكلمة فقط، يعني لو عدلنا على الكود السابق الى
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "HELLOOOO, LOOK AT YOU!";
let result = text.search(/LO\b/);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
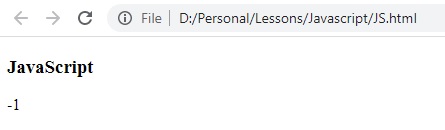
النص غير موجود.
الحرف uxxxx\
يتم البحث عن الحرف المطلوب Unicode character بالنظام السداسي العشري hexadecimal number
مثال :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Devkum Hello World!";
let result = text.match(/\u0057/g);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة
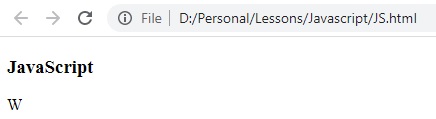
تحديد كميات البحث Quantifiers define quantities:
يمكن التحكم بكمية النتائج المطلوب عرضها في regular expression باستخدام مجموعه من الرموز الخاصة بذلك وهذه الرموز:
الرمز n+
في هذا الرمز يتم اجرء المطابقة لجميع الحروف المطابقة مع الحرف n (على الأقل حرف n واحد)
مثال:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Devkum We made it easy.";
let result = text.match(/e+/g);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
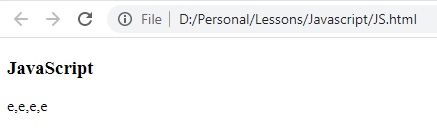
لاحظ ان تم اجراء المطابقة لجميع الحرف المطابقة للحرف e (ارجاع جميع الحروف)
الفكره ان بتم ارجاع التطابق في حال وجود حرف واحد على الأقل مساوي للحرف n
الرمز n*
يتطابق مع أي سلسلة تحتوي على صفر أو أكثر من تكرارات n،
مثال:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Devkum We made it eassssy.";
let result = text.match(/ea*/g);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
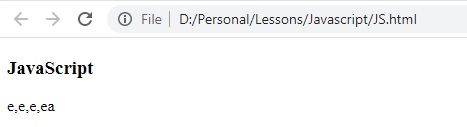
لاحظ ان تم ارجاع جميع التطابقات بعد الحرف e وأيضا بعد الاحرف ea
الرمز n?
يتطابق مع أي سلسلة تحتوي على صفر أو تكرار واحد لـ n
مثال:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Devkum We made it eassssy.";
let result = text.match(/ea?/g);
document.write( result);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
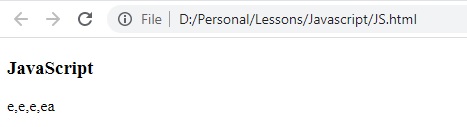
استخدام RegExp Object
يحتوي JavaScript على مجموعه من Object الخاصة ب RegExp حيث يحتوي على مجموعه من الخصائص والطرق المحددة مسبقًا.
منها :
()Using test
من خلال هذا object يتم ارجاع قيمة true او false حسب نتيجة المطابقة
مثال:
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Devkum We made it eassssy.";
const pattern = /e/;
document.write( pattern.test(text));
document.write("<br>");
</script>
</body>
</html>
النتيجة :
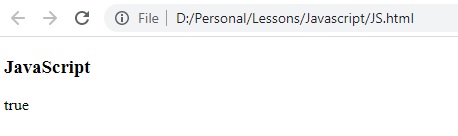
لان الحرف e موجد في السلسلة text لذا كانت النتيجة true
يمكن اختصار الكود السابق الى الشكل التالي :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = "Devkum We made it eassssy.";
document.write( /e/.test(text));
document.write("<br>");
</script>
</body>
</html>
الاختصار بكتابة regular expression قبل السلسلة مباشرة دون الحاجة الى استخدام pattern
()toString
تعمل هذه الطريقة على تحويل regular expression الى string ( بترجعو كما هو)
مثال
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let pattern = /Hello World/g;
let text = pattern.toString();
document.write(text);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
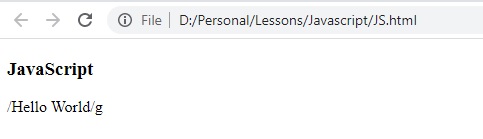
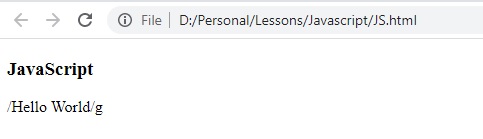
لاحظ النتيجة ان تم ارجاع regular expression الموجود داخل pattern كما هو (تم تحويله على string)
الاختصار
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
let text = /Hello World/g.toString();
document.write(text);
document.write("<br>");
</script>
</body>
</html>
النتيجة نفسها
()Using exec
هنا يتم البحث في سلسلة عن نمط محدد pattern، ويعيد النص الموجود ك object. إذا لم يتم العثور على تطابق، فإنه يقوم بإرجاع empty (null) object.
مثال :
<!DOCTYPE html>
<html>
<body onunload="">
<h3>JavaScript</h3>
<p id="Date"></p>
<script>
const obj = /e/.exec("Devkum We made it eassssy.");
document.write("Found " + obj[0] + " in position " + obj.index + " in the text: " + obj.input);
document.write("<br>");
</script>
</body>
</html>
النتيجة:
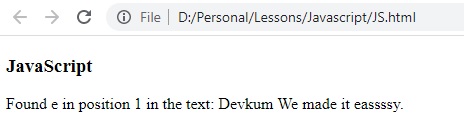
لاحظ ان نتيجة البحث عن الحرف e تم ارجاعها على شكل object وقدرنا نوصل لمجموعه من الخصائص لهذا object مثل المكان باستخدام الامر obj.index والحرف الذي تم البحث عنه باستخدام obj[0] والنص كامل باستخدام obj.input


اترك تعليقك